Table of Contents
The previous steps were all about getting the new backend project, engine, and benchmark description setup to run. Now we need to actually implement our benchmark logic by implementing each of the 7 virtual functions defined in hebench::cpp::BaseBenchmark which map to the hebench::APIBridge backend interface. For this example, we will go over each function and provide an overview of what that function needs to do and the tutorial implemention using SEAL.
We already have our original workflow that executes the element-wise addition operation, and we want to benchmark, as shown during the introduction. To write our test into HEBench, we must understand the detailed workload description. All supported workloads can be found at HEBench Supported Workloads . In particular, Vector Element-wise Addition Workload contains the detailed information for our workload, including number, format, and layout of the parameters; a detailed description of the benchmarks algorithm and how each of the previously described parameters are used; and the expected format and data layout of the benchmark input and results.
Communication between Pipeline Stages
Benchmarks are required to implement a number of functions as defined in the API Bridge. These functions are called by the frontend as part of the testing procedure. Each function will receive some parameters as input, perform some expected operation, and then pass the results back to the frontend which will use the returned results as input to later functions in the flow. This logical flow must be respected by the different functions we have to implement.
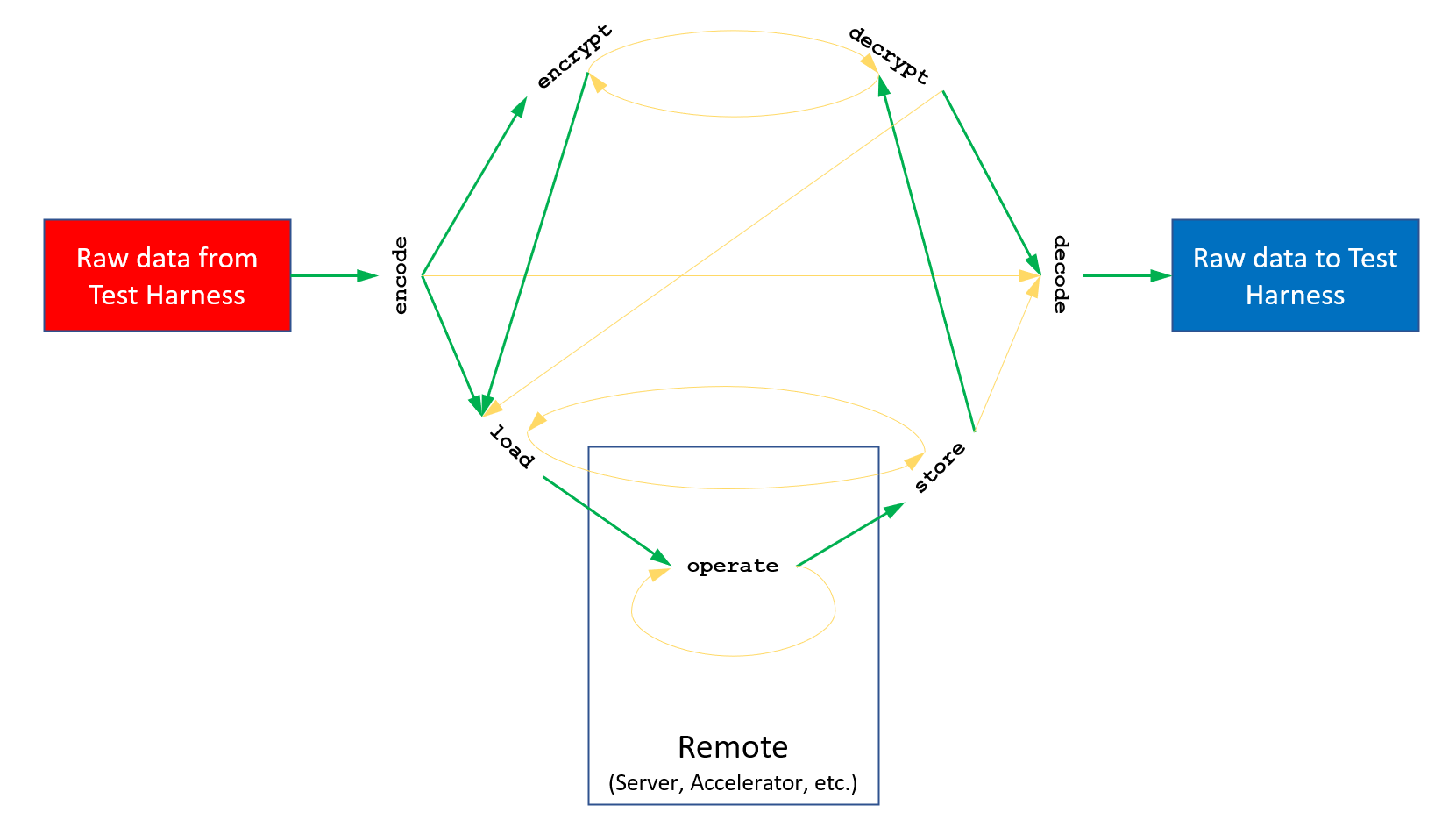
API Bridge Function pipeline flow chart.
For more information on the pipeline flow, check API Bridge Function Pipeline Chart .
To enable a high amount of flexibility and enable the widest variety of implementations with the exception of the encode and decode's hebench::APIBridge::DataPackCollection parameters, all communication is done via hebench::APIBridge::Handle objects. These handle objects are completely opaque to the Test Harness and it is up to the backend to decide what is stored in each handle at each step of the pipeline.
C++ wrapper offers a series of helper methods to ease the creation and data wrapping in these handles. While it is not necessary to use these methods, it is recommended for code correctness, robustness, and clarity. See hebench::cpp::BaseEngine::createHandle() and hebench::cpp::BaseEngine::retrieveFromHandle() for details.
All the methods that will be called from Test Harness should receive validated inputs and C++ wrapper performs some basic validation as well (such as null handle checks); however, it is a good idea to validate those inputs in the case where we are using incompatible versions between Test Harness and our backend's required API Bridge, or any other errors occur. For clarity, though, most validation will be omitted in this tutorial (or handled with an assert call).
Always throw hebench::cpp::HEBenchError from C++ wrapper to report errors. C++ wrapper will understand this error type and inform Test Harness accordingly. Throwing other exceptions is valid, but they result in Test Harness receiving HEBENCH_ECODE_CRITICAL_ERROR from the backend. There are some examples throughout the tutorial code.
Mapping Workflow to API Bridge Pipeline
Our task is to map our workflow to the stages of the API Bridge pipeline (each function in the flow graph).
In our example, we already have a workflow that is easy to map, since we have organized stages into function calls. We copy our workflow declaration into the benchmark class (with some extra helper methods) as shown here:
We also define some wrappers as internal representation for the parameters to our workflow methods. These are needed to keep track and retrieve the inputs and outputs of the stages as they are wrapped into opaque handles.
The next steps follow the logical flow order of the function pipeline.
Steps
0. Benchmark Initialization
During construction of our actual benchmark class, TutorialEltwiseAddBenchmark, we validate the workload flexible parameters that were passed for this benchmark. These must be checked because users can use benchmark configuration files to pass different parameters.
Afterwards, other benchmark initialization steps are performed. In this case, we are initializing our original workflow and the SEAL context for our operations.
1. encode
hebench::cpp::BaseBenchmark::encode wraps the hebench::APIBridge::encode() function. In the default behavior: encode receives a call for all operation parameters that will be in plain text, and another call for all encrypted, in no specific order. This method should encode all parameters received via p_parameters, bundle them together using an internal format that will make easier to recover from other methods (such as encrypt and/or load) and return them in an opaque handle.
Encode is responsible for rearranging and encoding this data into a format and new memory location that is compatible with the backend.

API Bridge Encode flow chart.
For our benchmark, the element-wise add operation has only 2 operands. We have specified in the benchmark description that first is plain text and second is ciphertext. According to documentation, Test Harness will encode all parameters that ought to be encrypted in a single call to encode, and all the plain text in another call.
First, we validate the data packs. Our backend supports variable sample sizes, but since we are specifying hard values for number of samples per parameter in the benchmark description, we make sure we are receiving the correct number of samples here. We can set the specified count to 0 in the description and accept variable number of samples instead.
Once we know the data pack is valid, we must arrange the raw data coming from Test Harness to be compatible with the input to our original encoding method. In offline category, each operation parameter contains a collection of samples for said parameter. Since the incoming data which is already in the expected format for our original encoding, we just have to point the data structures to the appropriate memory locations. Refer to the workload description reference for information on the data layouts.
Each sample coming from Test Harness is contained in a memory buffer wrapped in a hebench::APIBridge::NativeDataBuffer structure. A sample for element-wise add is a vector of scalars of the requested type during benchmark description (64-bit signed integer in this example). The number of elements in this vector should be the same as received from the workload parameters during construction of this object.
Since we arranged the input from Test Harness into the format expected by our original encoding method, now we get to call it to do our actual encoding.
From the default pipeline, the result of the encoding will be passed to encrypt() or load() methods, which correspond to our workflow encryption and (for lack of load step) operation. So, to return the encoding, we wrap it in our internal representation. This representation can be as simple or as sophisticated as we want. The idea is to facilitate access to the wrapped data by methods that will be receiving it.
Then, we hide our representation inside an opaque handle to cross the boundary of the API Bridge. We use hebench::cpp::BaseEngine::createHandle() helper method to generate the handle for our return value.
The tag serves to keep track and identify that we are receiving the correct handles in the pipeline. The values for the tag are arbitrary, for backend to use for this purpose, and thus, we define an internal convention for tagging our handles.
We use move semantics when creating the handle to avoid copying possibly large amounts of data here. But, again, this is all backend specific, and any particular implementation is free to return the data in whichever way fits best.
This is the complete listing of our encode() method:
2. encrypt
hebench::cpp::BaseBenchmark::encrypt is responsible for receiving the plain text output from encode() and encrypting it into ciphertext.

API Bridge Encrypt flow chart.
Here we retrieve our internal representation from the opaque handle representing the encoded data:
We want input to encrypt() to be of type InternalParam<seal::Plaintext>. It is expected all data returned by all methods feeding into encrypt() return data in this format. This data must be wrapped into an opaque handle with tag InternalParamInfo::tagPlaintext. Note that this is our internal convention, established to facilitate communication among our implementation of the backend methods. Test Harness is not aware of our convention. It will only pass our handles in the order defined by the workload pipeline flow.
Since our internal representation is designed to maintain the input format expected by our original methods, now we just need to call the encryption from the original workflow.
Finally, we wrap our encrypted parameter in our internal representation, hiding it inside an opaque handle to cross the boundary of the API Bridge. This handle will be passed to method load() in the default pipeline.
This is the complete listing for our method:
3. load
Method hebench::cpp::BaseBenchmark::load has two jobs. The first and foremost is to transfer the data to the location where it will be used during the operation, whether it is a remote server, accelerator hardware, or simply local host. The second job, which is usually bundled with the first, is to rearrange the data, if needed, so that the operation itself is not burdened with unnecessary data manipulation. While most of the data manipulation and layout should have happened during encode(), any last minute arrangements should be done here.

API Bridge Encode flow chart.
This method will receive all handles resulting from previous calls made to encode() and encrypt() methods. Based on the workload pipeline flow specified in the documentation we know what we will be receiving in those handles, and it is up to our internal convention to extract our information from the opaque handles and organize it for the operation.
Since, for this example, the data will remain in the local host, we do not need to use any extra functionality to transfer it. We will only arrange the order of the parameters to directly match our original workflow operation into a pair (2-tuple).
It is important to note that if the input handles are destroyed, the generated output handles should not be affected, according to the documentation specification for API Bridge. Also, it is good practice for a backend to avoid modifying the underlying data contained in input handles. This means, that if we only need to pass the data wrapped in an input handle along as return value, we must either duplicate the handle, or create a copy of the data that will not be modified or destroyed if the original data from the input handle is modified or destroyed. In this case we will duplicate the data. We show the handle duplication in the store() method.
We complete our method, as usual, by wrapping our representation inside an opaque handle to cross the boundary of the API Bridge. This handle will passed to method operate().
The full listing for our load() method is below.
4. operate
hebench::cpp::BaseBenchmark::operate is expected to perform the benchmark operation on the provided combination of encrypted and plain text input data.

API Bridge Encode flow chart.
In practice, operate() should perform as fast as possible. Also, it should never return until all the results for the requested operation are available on the remote host or device and ready for retrieval from the local host.
To start, we obtain our internal input representation from the opaque input handle. This is the handle returned by method load().
Input data for the operation has been packed into a single handle by method load(). Usually, all of the data samples supplied by Test Harness is encrypted and/or encoded. Indexers are used by Test Harness to point to a portion of input samples to use for the operation, requesting the backend to operate on a subset of the input instead of the complete dataset.
Note that, unless otherwise specified, in offline mode the complete dataset is used, and thus, needing to use the indexers is rare.
In this tutorial, the backend does not support operating on subsets of the dataset. In the following code, we simply validate the indexers and move on. However, support is not difficult to add in this scenario using spans to point to portions of the input dataset. It is left as an exercise to the reader.
Since we obtained the inputs for our operation in the correct format, next we pass them to our original workflow.
As a side note: if operate is executing on an external device that requires some sort of data streaming, this can be mimicked in offline mode as follows:
- Load first chunk of data during loading phase.
- (in parallel) Operate on current chunk of data. (in parallel) If more data is available, stream next chunk of data from host into remote.
- If more data is available, go to ii.
- Wait for all ongoing operations to complete.
Finally, we wrap the result in our internal representation, and hide it inside an opaque handle to cross the boundary of the API Bridge. This handle will be passed to method store() in the default pipeline.
Full listing of the operate() method follows.
5. store
hebench::cpp::BaseBenchmark::store is responsible for copying results back from our remote device into the local host.

API Bridge Encode flow chart.
We are on the downward slope now. We must store, decrypt, and decode the results of the operation.
The input handle for method store() is the handle returned by operate. In a backend where the operation occurs on a remote device (server, hardware accelerator, etc.) the result of the operation remains on the remote after completion. The job of this method is to transfer that result from remote into the local host for the rest of the pipeline.
As per specification of API Bridge, any extra handles should be padded with zeroes. So, we take care of that first to avoid extra work later.
Since the host and remote are the same for this example, we do not need to perform any retrieval operations. We will just duplicate the handle to ensure that if the input handle is destroyed, the resulting handle remains.
Note that handle duplication does not perform a deep copy of the underlying data. Both, the original and duplicated handle will refer to the same internal data and modifying one will effectively reflect the changes in the other. While the specification calls for persistence of results after destruction of the input handles, it does not mention consistency of the data. Such consistency is backend dependent. To ensure data consistency, though, it is good practice for a backend to not modify the underlying data of an input handle.
This duplicated handle will be passed as input to the decrypt() method in the default pipeline.
The full listing for this method is:
6. decrypt
hebench::cpp::BaseBenchmark::decrypt receives result ciphertexts output from store() and decrypts them into plaintexts.
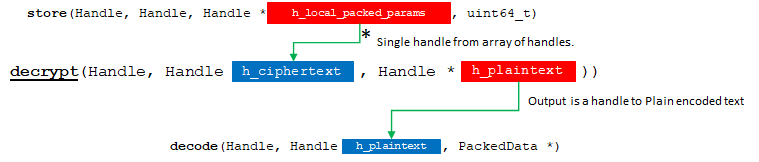
API Bridge Encode flow chart.
As before, we retrieve our internal representation from the input handle. This is coming from store() in the default pipeline.
Next, we use our original workload decryption.
And we finish by wrapping the decrypted data in our internal representation and returning it inside an opaque handle through the API Bridge. This handle will be passed to method decode() in the default pipeline.
Full listing of this method follows.
7 decode
hebench::cpp::BaseBenchmark::decode is responsible for receiving encoded result data and writing its decoded form back to the output buffer.

API Bridge Encode flow chart.
Here we decode the data from the operation result and arrange it into the format expected by Test Harness for validation. We touch upon some specification details regarding possible excess or insufficient data.
As usual, we retrieve our internal representation from the input handle. This handle comes from method decrypt() according to the default pipeline.
Having our internal representation, we call the original workload version to decode our result.
Finally, we rearrange the result clear text in the format expected by Test Harness, respecting the specifications.
The hebench::APIBridge::DataPackCollection* parameter points to pre-allocated memory into which the decoded results must be written. The exact size, format, data type, etc. is detailed in the workload description which for this example is Vector Element-wise Addition Workload .
We are returning the result, so, we find the data pack corresponding to this result component from the pre-allocated buffers. If we had more than one component, we would loop on the components and decode each. This method will throw an exception if the requested component is missing from the data packs passed by Test Harness into decode() (note that this should not happen in a default workload pipeline).
According to specification, we must decode as much data as possible, where any excess encoded data that won't fit into the pre-allocated native buffers shall be ignored. If the buffers fit more data than we have, we only set as much as we have and do not touch the excess space.
Find the complete listing for this method next.
At this point, the default pipeline is completed. Test Harness takes over, performs validation of the result, and, if result is correct, generates the benchmark reports.
Make sure to perform appropriate cleanup in the destructor of your classes. Test Harness will request destruction of resources when they are no longer needed.
Tutorial steps
Tutorial Home
Preparation
Engine Initialization and Benchmark Description
Benchmark Implementation
File References